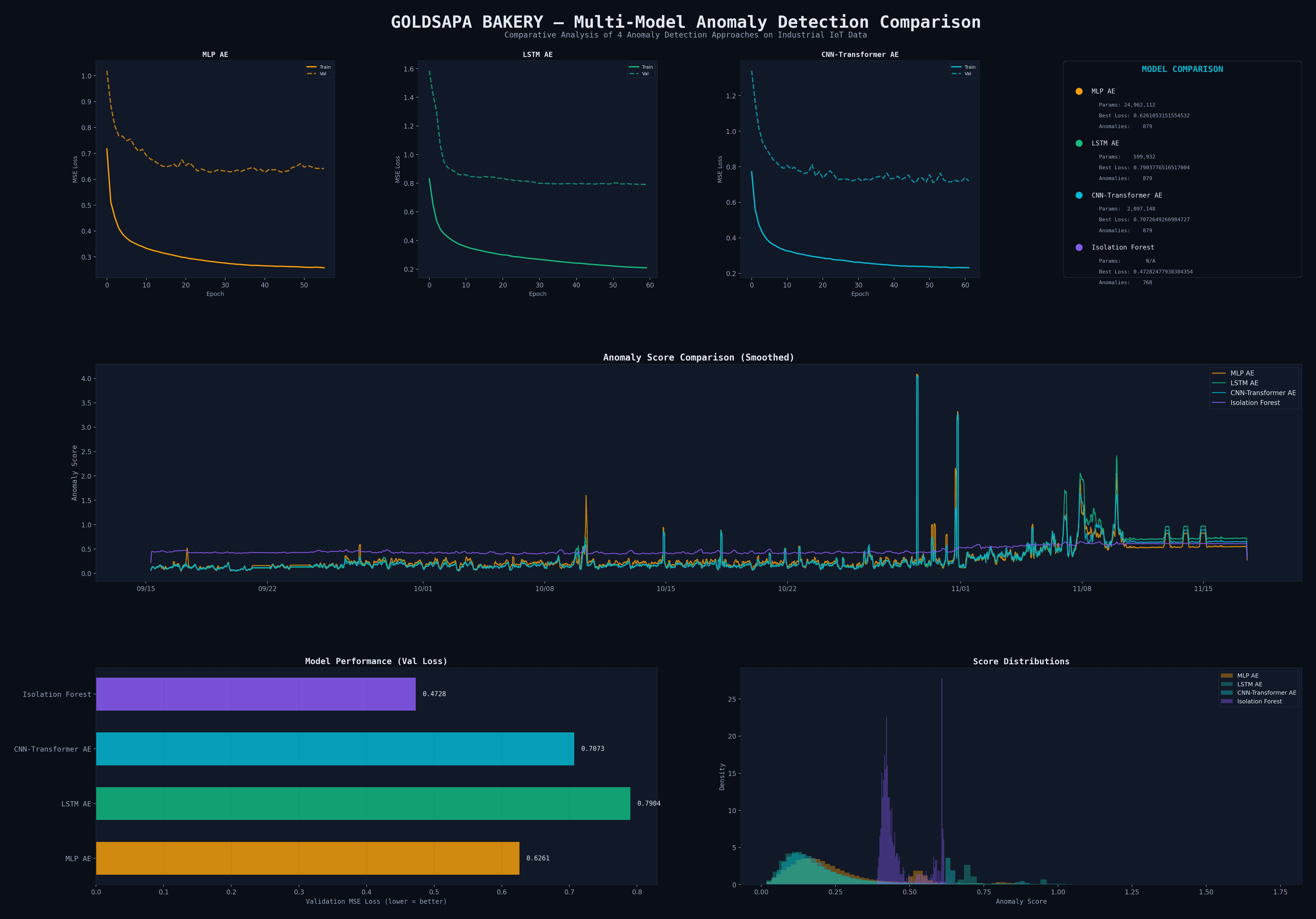
Comparative Analysis
Model Comparison
4 approaches tested on 87,813 industrial IoT datapoints
Architecture
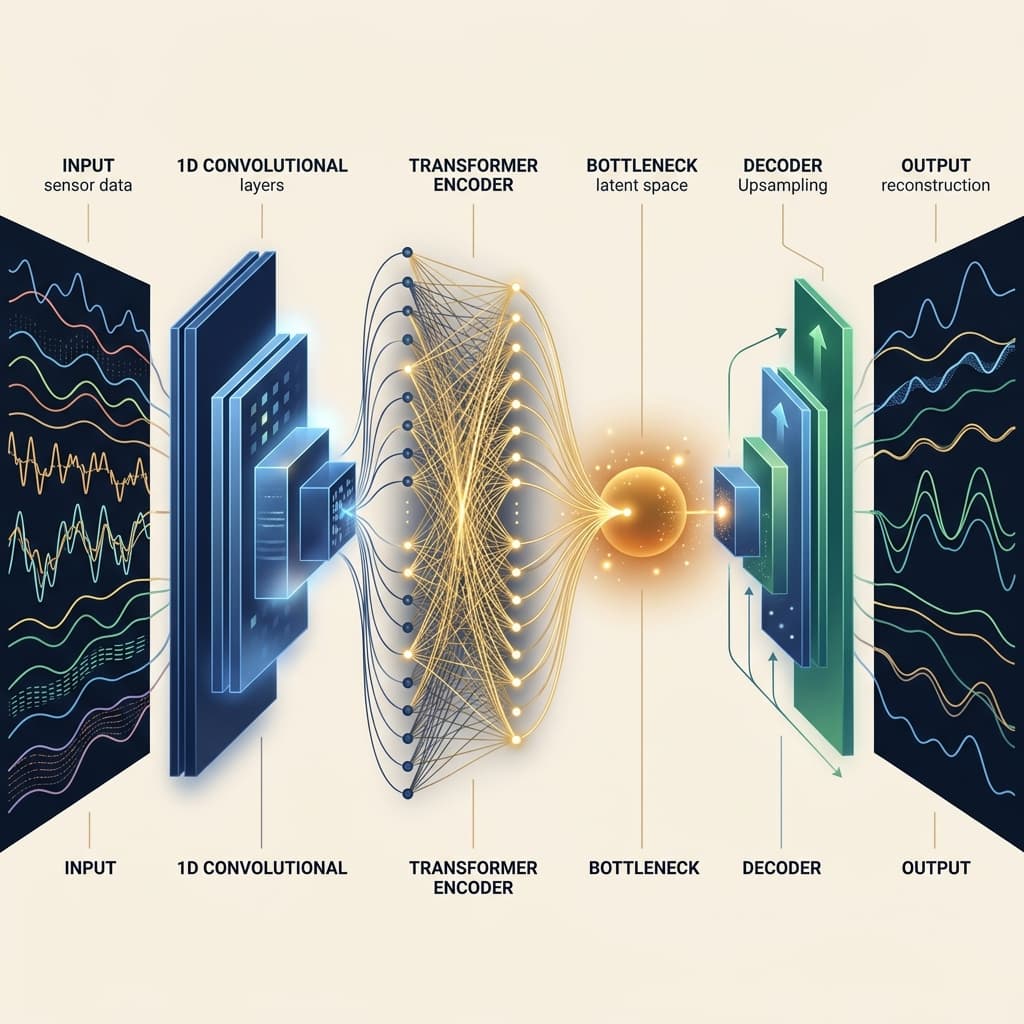
CNN-Transformer Autoencoder
2,097,148 parameters
MLP Autoencoder
BaselineVal Loss
0.6261
Feed-forward AE. Flattens temporal data, no time awareness. Good baseline but overfits with 25M params.
Params
24.9M
Epochs
56
✓ Advantages
· Fast training
· Low val loss
✗ Limitations
· No temporal patterns
· Overfitting risk
LSTM Autoencoder
RNN ClassicVal Loss
0.7904
Recurrent encoder-decoder with LSTM cells. Classic time-series approach, compact but sequential.
Params
600K
Epochs
60
✓ Advantages
· Temporal awareness
· Compact architecture
✗ Limitations
· Vanishing gradients
· Sequential processing
CNN-Transformer AE
Best ⭐Val Loss
0.7073
Hybrid: CNN extracts local patterns, Transformer captures global dependencies via self-attention.
Params
2.1M
Epochs
47
✓ Advantages
· Local + global patterns
· Parallelizable
✗ Limitations
· Higher memory
· Requires GPU
Isolation Forest
Non-DLVal Loss
0.4728
Tree-based outlier detection. No neural network — fast but can't learn complex temporal patterns.
Params
N/A
Epochs
—
✓ Advantages
· No GPU needed
· Interpretable
✗ Limitations
· No temporal learning
· Less sensitive
Multi-Model Dashboard
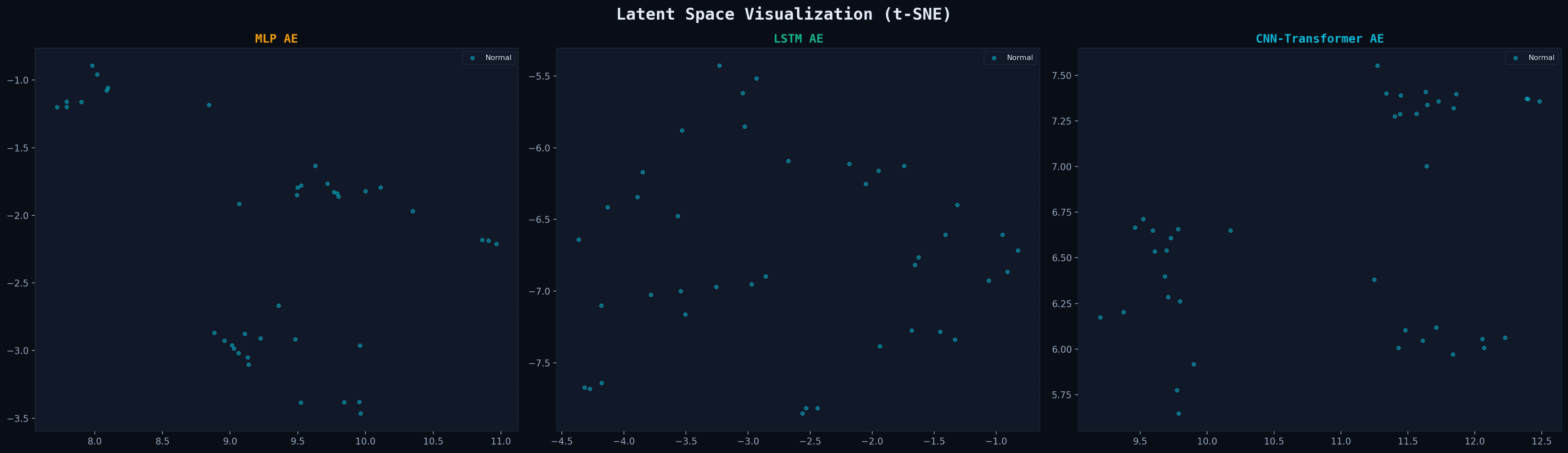
Latent Space (t-SNE)
Dimensionality reduction of encoder outputs — visualizing learned representations
GPU Compute
Training Pipeline
NVIDIA RTX 4070 Ti SUPER · CUDA 12.8